


Nostalgia setentera: el audio digital vs el analógico*
Francisco Delahay

Imagen: Salvador Gutiérrez
En una atmósfera plagada de recuerdos, un grupo de amigos analiza las ventajas y desventajas de haber pasado del LP al CD.
Es una calurosa tarde de verano. Me he reunido con algunos de mis compañeros de secundaria para gozar de un café en una soleada plaza de la Ciudad de México. La tarde dominguera está poblada de vendedores de incienso y puestos clandestinos repletos de discos digitales y libros. La atmósfera se impregna de ritmos provenientes del huéhuetl de los concheros que danzan a unos metros de nosotros. Todo esto contribuye a crear un ambiente en el que inevitablemente salen a la superficie los recuerdos de la adolescencia. La cabeza de Raúl, ahora calva, en aquel entonces estaba poblada por una densa cabellera. El cuello de Benjamín, antes adornado por unos colguijos, ahora ostenta una elegante corbata que lo acompaña diariamente al trabajo.
Comienzo a percibir los síntomas de lo que llamo el síndrome de la nostalgia setentera. Éste se da cuando un grupo de personas de entre treinta y cuarenta años empieza a rememorar su juventud. El síndrome puede ser tan grave que el paciente desprecie todas las expresiones culturales de épocas posteriores. Así, nos enfrascamos en una discusión harto común entre gente de nuestra generación. Benjamín comienza:
—¿Qué opinan ustedes? Yo creo que esto del audio digital es un patraña. Nada como los viejos acetatos. Sin duda suenan mejor. Además, los LP de antes traían carteles y chácharas diversas.
—Pues yo no estoy de acuerdo —dice Raúl—. Los discos compactos (CD) son más modernos y suenan mucho mejor. El sonido es limpio y no se van degradando con el uso como los LP. Pero —añade, dirigiéndose a mí—, ¿tú qué piensas?
—Ejem... pues... no cabe duda de que los viejos LP con sus enormes fundas tenían su atractivo y no son pocos quienes todavía están dispuestos a invertir sus morlacos en un buen tocadiscos. Pero creo que saber cuál formato es mejor no es nada sencillo. Propongo, pues, que nos vayamos a mi casa. Tengo una vasta colección de LP de los 70: Chicago, los Osmond Brothers, Boston, Klatú e incluso clásicos tales como Silver Convention. Podemos compararlos con mi colección de CD remasterizados. ¿Qué opinan, se avientan?
Veo un fulgor aparecer en las miradas de Benjamín y Raúl. Tienen cuerpo de treintones, pero alma de adolescentes.
Nos encaminamos a mi casa. Ahí examinamos algunos de mis discos compactos. En la parte de atrás de uno de estos dice: "Remasterizado de las cintas analógicas originales, versión definitiva". Lo pongo en el reproductor y todos los presentes están de acuerdo en que el sonido es brillante.
—Un momento —dice Raúl—, hay sonidos que no había escuchado antes. ¿Será posible?
La discusión gira ahora en torno a las diversas variables que pueden haber contribuido a este cambio en nuestra percepción auditiva. Ésta no se lleva a cabo sólo en el oído. También depende del cerebro. La audición tiene una parte sensorial y otra intelectual. Ninguno de nosotros, como es de esperarse, toma en cuenta el deterioro del aparato auditivo debido a la edad; tampoco el hecho de que, con la experiencia, se agudiza la parte intelectual de la percepción auditiva.
Nadie es imparcial en esta discusión. Raúl, como ya sabemos, está a favor de los CD, mientras que Benjamín prefiere los LP.
Al cabo de un rato, la plática los exaspera y ante mi silencio, Benjamín y Raúl me piden una explicación.
—A ver dinos, ¿cuál es la diferencia entre los discos de acetato y los compactos?
La percepción auditiva y el cerebro
La percepción del sonido no es sólo el resultado de la vibración mecánica de las partes móviles del oído. También interviene el cerebro, que traduce los impulsos nerviosos que le transmite el oído en sensaciones auditivas. El cerebro está dividido en dos hemisferios: derecho e izquierdo. Los hemisferios cerebrales no son idénticos. Las asimetrías del cerebro se traducen, entre otras cosas, en asimetrías en las funciones que intervienen en el proceso auditivo. El hemisferio izquierdo interviene cuando realizamos actividades analíticas, por ejemplo cuando nos enfrentamos a problemas matemáticos o gramáticos. El hemisferio derecho se activa cuando estamos en situaciones relacionadas con la percepción espacial, por ejemplo al manejar.
Esto significa que la percepción de los distintos elementos que constituyen el sonido se da en distintas regiones del cerebro. Si escuchamos una sinfonía, puede que nos interese distinguir la manera en que interactúan los instrumentos que participan en un pasaje. En esta operación es importante la capacidad de distinguir el sonido de un instrumento del de otro, es decir, separar mentalmente las frecuencias que componen cada sonido (la sección de vientos y la sección de cuerdas) y asociarlas mentalmente a sus instrumentos correspondientes. En esta operación intervendrá seguramente el hemisferio izquierdo. Mientras tanto, el análisis espacial, es decir, dónde se ubican los sonidos dentro de la sala, se dará en el hemisferio derecho.

Audio analógico y audio digital
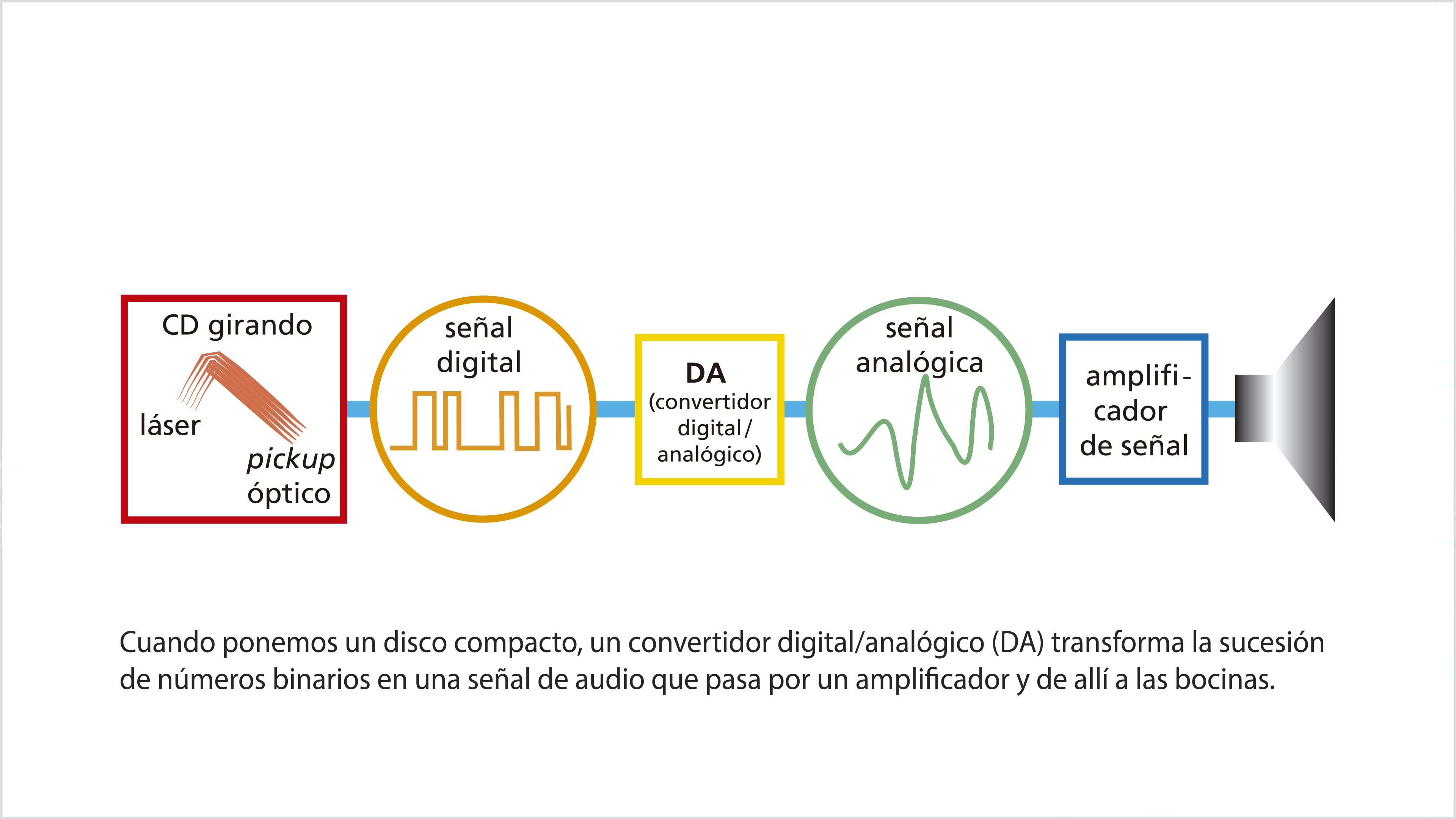
En un LP la aguja del tocadiscos vibra al pasar sobre las protuberancias de los surcos. Las vibraciones se transmiten a un imán, produciendo una corriente eléctrica oscilante cuyos altibajos son análogos a los de los surcos. Esta corriente eléctrica, a la que llamaremos señal de audio, es muy débil. Por ello es necesario transmitirla a un amplificador, que luego la comunica a las bocinas. Éstas, finalmente, reproducen las vibraciones del sonido grabado, que llegan a través del aire hasta nuestros tímpanos, dando lugar a una sensación auditiva. Decimos que es un proceso analógico porque la vibración de las bocinas, la señal eléctrica y los vaivenes de la aguja al pasar por los surcos son copia unos de otros.
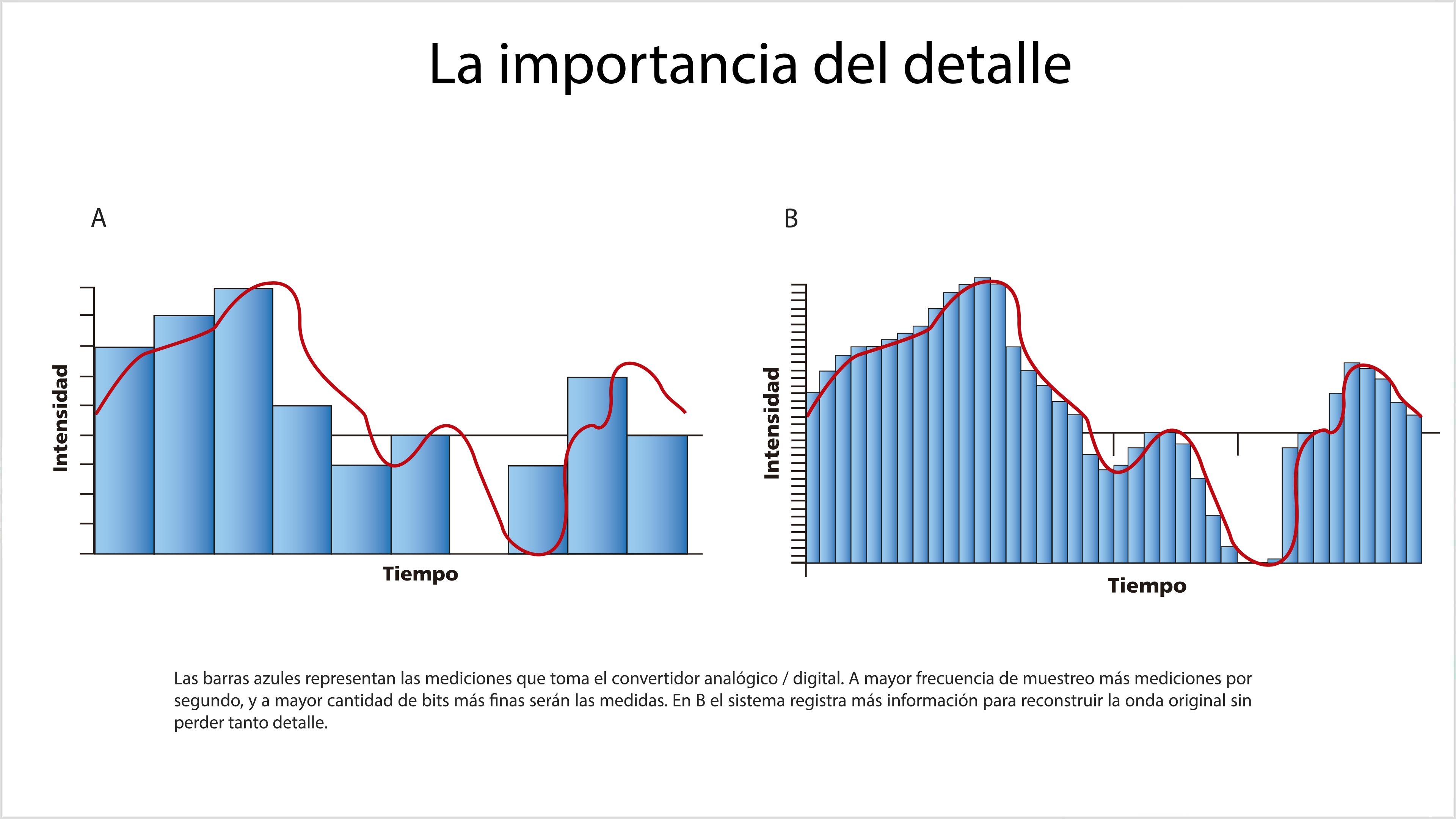
El disco compacto, a diferencia del LP, contiene información digital, es decir, que está codificada en forma de números binarios. El sonido ha sido captado por un micrófono que produce vibraciones analógicas, como en el caso de la aguja sobre el acetato. Las vibraciones, a su vez, producen una señal de audio que pasa a un convertidor analógico/digital (AD). El convertidor va midiendo la intensidad de la señal a intervalos regulares. Cada medición da un número entero. Este proceso se conoce como muestreo o sampleo.
El número de mediciones que efectúa el convertidor en un segundo se llama frecuencia de muestreo y se expresa en hertz. Es común utilizar una frecuencia de muestreo de 44.1 kilohertz (44 100 Hz). Cuando ponemos un disco compacto, un convertidor digital/analógico (DA) transforma la sucesión de números binarios en una señal de audio.
Nada es infalible
En efecto, la tecnología digital tiene sus bemoles. Hay diferentes tipos de distorsión en el mundo digital. Supongamos, por ejemplo, que grabamos el sonido de la hermosa voz de Cristina Aguilera cantando la nota "La" correspondiente a la octava central de un piano. Esta nota produce una onda de sonido que hace vibrar el aire 880 veces por segundo. Supongamos que nuestro convertidor DA está programado para realizar mediciones a una frecuencia de 900 Hertz, es decir 900 veces por segundo. Después reproducimos el sonido grabado a través de nuestras bocinas y lo que escuchamos no se parece ni lejanamente a lo que cantó Cristina. La frecuencia del sonido resultante (es decir, la nota que oímos) se puede calcular por medio de una fórmula llamada teorema del muestreo que se expresa de la siguiente manera:
frecuencia resultante = frecuencia de muestreo – frecuencia original
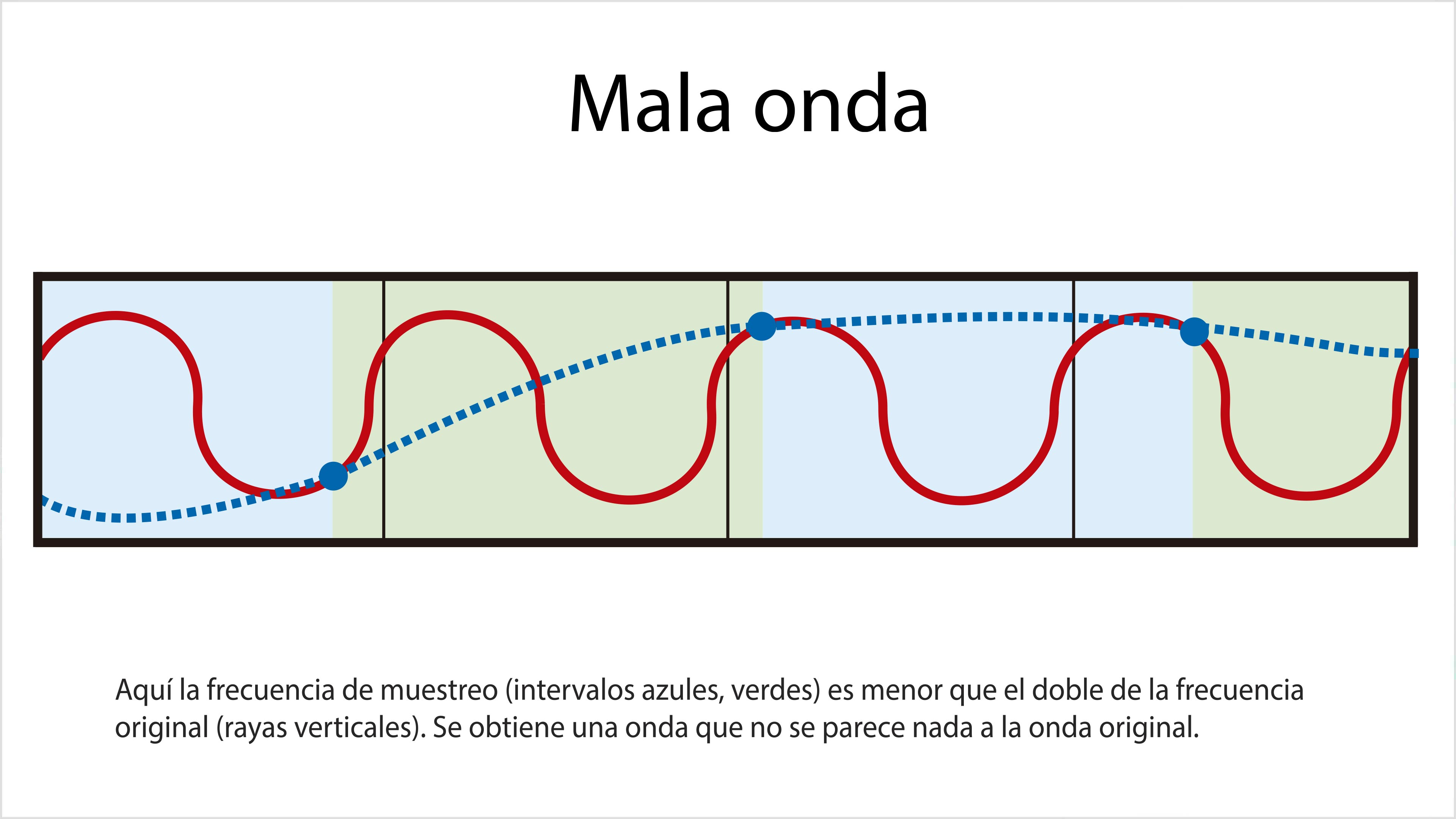
El resultado en este caso será un desagradable gruñido de 20 Hz (900 - 880 = 20), que podría resultarle atractivo a un elefante en celo, pero que para nuestros propósitos resulta inútil. A este tipo de distorsión se le llama en inglés aliasing.
Aunque el convertidor hizo las mediciones bien, al haberlas realizado a una frecuencia insuficiente se produjo un sonido de una frecuencia menor que la original. Por eso para reproducir un sonido se requieren por lo menos dos mediciones por cada ciclo de la onda de sonido original. Puesto que un oído humano en teoría no puede percibir frecuencias de más de 20 000 Hz, se ha convenido en que la frecuencia de muestreo óptima para el audio digital es de 44 100 Hz, es decir, más del doble de la frecuencia más alta que percibe el oído humano.
La frecuencia máxima que puede reproducir un sistema de audio se llama frecuencia de Nyquist de dicho sistema. La mayoría de los equipos de sonido tienen una frecuencia de Nyquist de 20 000 Hz. Por lo tanto, las frecuencias superiores a 20 000 Hz deberán eliminarse por medio de un filtro para evitar el efecto de aliasing.
En la naturaleza un sonido de 20 000 Hz será en realidad una combinación de vibraciones (armónicos) de 20 000 Hz, 40 000 Hz, 60 000 Hz, y todos los múltiplos de la frecuencia nominal. Los armónicos de un sonido de 20 000 Hz superan la frecuencia de Nyquist de cualquier sistema de audio y el micrófono los recoge aunque sean inaudibles para nosotros. Si no se instala el filtro, estas frecuencias quedarán grabadas y aparecerán sorpresivamente en la reproducción en forma de sonidos desagradables, como explica el teorema de muestreo. Por eso a estos filtros se les llama antialias.
En los primeros días del audio digital se utilizó un filtro antialias para contrarrestar este efecto. El filtro no dejaba pasar ninguna frecuencia que fuese mayor que la frecuencia de Nyquist. El resultado fue que los sonidos agudos resultaban desagradables y poco naturales.
Números binarios
Los números binarios son el alfabeto de las computadoras. La mínima expresión de este sistema es el bit, que puede ser un 1 o un 0. Cuando se juntan varios bits, se forma un byte, el equivalente a una palabra en un lenguaje humano. Un byte puede estar formado de 4, 8, 16, o 32 bits (como en Windows 95, 98, 2000 y XP).
En un sistema de un bit es posible representar dos valores. Un sistema de dos bits es capaz de representar cuatro valores: 00=0; 01=1; 10=2; 11=3. Un sistema de 4 bits, en cambio, puede representar un total de 16 valores; y así sucesivamente.
Rapsodia binaria
Éste no es el fin de los problemas para el audio digital. Cada una de las mediciones que hace el convertidor DA arroja un número binario. Éste se compone de una serie de unos y ceros, a los cuales llamamos bits. Mientras más bits utilicemos para expresar las mediciones, más exactas serán. Claro está que ninguna medición es totalmente exacta, porque tenemos una cantidad finita de números a nuestra disposición para expresarla. Un número de ocho bits —10100011, por ejemplo— nos podrá dar 256 valores para nuestra medición, mientras que un número de 16 bits nos dará 32 000 valores. Si, por ejemplo, la intensidad de la señal es de entre 54 y 55 unidades, nuestro convertidor DA registrará 54 o 55, pero nunca 54.3. Este redondeo se llama error de cuantización. Una cantidad insuficiente de bits produce una distorsión debida al error de cuantización y se conoce como ruido de cuantización. Este ruido se hace perceptible cuando, por ejemplo, un archivo de audio digital de 16 bits se convierte en uno de ocho bits. La calidad del sonido puede cambiar considerablemente.
Ahora imagínate que oyes a Elton John terminar una canción con un acorde largo que se va desvaneciendo. En un momento dado las vibraciones de las cuerdas se vuelven muy tenues. Primero se confunden con el ruido ambiental, es decir, con la ventilación, la respiración del público, nuestra propia respiración, uno que otro estornudo. Poco después, dejamos de percibirlas. Sin embargo, Elton, cuya cabeza se encuentra a unos centímetros de las cuerdas del piano, todavía percibe vibra ciones y sigue presionando las teclas. Nosotros ya hemos dejado de percibir el sonido, pero éste continúa y nuestra grabadora digital lo está captando. Llega un momento en que el sonido es tan débil, que el convertidor no sabe si asignarle a la intensidad el valor 0, o el primer valor positivo disponible. El convertidor opta por darle el primer valor positivo. Así se da una distorsión nada deseable en la que los sonidos que naturalmente no oiríamos se amplifican a un nivel audible junto con los otros ruidos ambientales. Por esta razón se utiliza un filtro llamado en inglés dither, que crea una combinación de todos estos ruidos al mínimo nivel audible, lo que da la sensación de un murmullo ambiental. Nuestra apreciación subjetiva entonces resulta ser la de un acorde que desaparece de manera natural.
Formatos de audio e Internet
Todas las computadoras PC tienen un programa de grabación de sonido que produce archivos con la extensión WAV. Un archivo WAV con resolución de 16 bits y frecuencia de muestreo de 44 100 Hz tendrá, si la grabación es buena, la misma calidad que un CD. Pero en Internet es raro encontrar archivos de este tipo porque ocupan mucha memoria y tardan mucho en "bajar" de la red. Cuando uno pone archivos de audio en la red, conviene sacrificar la calidad sonora para obtener archivos más pequeños. Lo más común son los formatos que permiten la compresión y lo que se conoce como streaming. Compresión quiere decir que del archivo original se eliminan las frecuencias redundantes de una manera tal que puedan recuperarse a la hora de la reproducción.
Streaming se refiere a un proceso mediante el cual el archivo se va "bajando" desde una página web a medida que se va utilizando en vez de guardarse primero en el disco duro, de modo que no acapare los recursos de la computadora. Al preparar el archivo es importante tomar en cuenta cuántos bits por segundo se requieren para que la transmisión por la red sea de calidad suficiente, considerando que la mayoría de los usuarios utilizan módems de 56 000 bits por segundo, o incluso menos.
Algunos de los formatos más comunes llevan la extensión RA o RAM (Real Audio Media), y MPEG (Moving Pictures Engineering Group) MPEG es un formato "abierto", es decir, que cualquiera lo puede emplear y modificar a su conveniencia sin pagar derechos de autor. Hace poco, los laboratorios Fraunhofer de Alemania sacaron partido de este hecho y pusieron en circulación el formato MP3 (MPEG layer 3), que permite comprimir el archivo original hasta 12 veces sin pérdida notable de la calidad sonora.
Formatos de audio e Internet
Todas las computadoras PC tienen un programa de grabación de sonido que produce archivos con la extensión WAV. Un archivo WAV con resolución de 16 bits y frecuencia de muestreo de 44 100 Hz tendrá, si la grabación es buena, la misma calidad que un CD. Pero en Internet es raro encontrar archivos de este tipo porque ocupan mucha memoria y tardan mucho en "bajar" de la red. Cuando uno pone archivos de audio en la red, conviene sacrificar la calidad sonora para obtener archivos más pequeños.
Lo más común son los formatos que permiten la compresión y lo que se conoce como streaming. Compresión quiere decir que del archivo original se eliminan las frecuencias redundantes de una manera tal que puedan recuperarse a la hora de la reproducción.
Streaming se refiere a un proceso mediante el cual el archivo se va "bajando" desde una página web a medida que se va utilizando en vez de guardarse primero en el disco duro, de modo que no acapare los recursos de la computadora. Al preparar el archivo es importante tomar en cuenta cuántos bits por segundo se requieren para que la transmisión por la red sea de calidad suficiente, considerando que la mayoría de los usuarios utilizan módems de 56 000 bits por segundo, o incluso menos.
Algunos de los formatos más comunes llevan la extensión RA o RAM (Real Audio Media), y MPEG (Moving Pictures Engineering Group) MPEG es un formato "abierto", es decir, que cualquiera lo puede emplear y modificar a su conveniencia sin pagar derechos de autor. Hace poco, los laboratorios Fraunhofer de Alemania sacaron partido de este hecho y pusieron en circulación el formato MP3 (MPEG layer 3), que permite comprimir el archivo original hasta 12 veces sin pérdida notable de la calidad sonora.
Trampas
—¡Ah, ya lo sabía! —exclama Raúl—. ¡El mundo digital está lleno de trampas!
—Aún así —contesto— el rango dinámico de un disco compacto, que es el intervalo entre el sonido más débil y el más fuerte, es superior al de un casete o al de un disco de acetato. El rango dinámico también está determinado por el número de bits y se expresa en decibeles (unidad de intensidad auditiva que se abrevia Db). El rango dinámico de un buen sistema de audio analógico es de unos 80 Db, mientras que el de un convertidor de ocho bits es de 48 Db. Es decir que, efectivamente, los primeros sistemas de audio digital eran peores que los sistemas analógicos. Sin embargo, los sistemas de 16 bits tienen un rango de 96 Db, el cual ya es superior a los mejores sistemas analógicos.
—Pero todos los oídos son diferentes
—dice Raúl—. ¿Cómo saben los fabricantes de audio que nadie podrá percibir estas frecuencias?
—¡Ah! Ésa es la gran interrogante. Hay evidencia de que, si bien no percibimos vibraciones de más de 20 000 Hz, éstas tienen efectos psicológicos y fisiológicos que contribuyen de manera importante a nuestra experiencia auditiva. Pero no nos preocupemos más de estos menesteres y disfrutemos de esta joyita: mi disco en acetato de Barry White.
Así continuó el resto de nuestra soleada tarde dominical, en medio de una agradable nostalgia setentera.
Francisco Delahay es musicólogo e imparte clases de multimedia en el Politécnico de Jyväskylä, Finlandia.








